Dealing With Fire, Part 1: QA Crises and the First Line of Defense
A QA crisis rarely knocks politely, it usually shows up in the middle of a normal day. One moment everything looks fine, and the next, dashboards turn red, customers hit roadblocks, or a service chain starts to unravel.


When that happens, and after DevOps or other engineering teams debrief, every eye turns to QA asking, “What happened?”
But the truth is, a crisis never begins at the moment you see it. It starts much earlier with overlooked assumptions, rushed decisions, weak gates, or risks no one had time to evaluate.
By the time it reaches production, the fire has already been burning for a while.
That is why this first part looks at what truly counts as a QA crisis and where your first line of defense begins.
Not with heroics in production, but with the practices that keep small issues from ever becoming emergencies.
What Constitutes a Crisis in QA/QE?
Not every bug is a crisis. In QA and QE, a crisis is the moment a failure becomes big enough to threaten customer trust, business revenue, or the credibility of the team responsible for quality.
These events look sudden from the outside, but almost always, the conditions that caused them built up quietly over time.
Most QA crises tend to fall into three broad categories, each with its own pattern, pressure, and consequences.
Production Crises
These are the most visible and the ones that trigger immediate urgency.
A release goes out, dashboards light up, users experience errors, and the organization pivots into firefighting mode.
Production failures escalate because the impact is immediate.
IBM found that a defect caught in production is up to 100 times more expensive to fix than one caught early in development.
Gartner estimates that downtime for large enterprises costs 5,600 dollars per minute. In highly distributed systems, even a small error can ripple outwards.
Dynatrace’s 2024 report noted that 64% of enterprises experienced a major incident last year caused by microservice dependencies.
Production crises often include:
- Critical bugs affecting end users: A missing check, an expired API key, or a regression in authentication can instantly block thousands of users.
- Failed releases requiring rollback: Rollbacks sound safe but are risky. They can create data inconsistencies, break idempotency, or leave transactions stuck mid-flight.
- Cascading failures in distributed systems: A dependency slows down, queues build, retries spike, and suddenly, unrelated services begin failing.
- Performance degradation under load: Memory leaks, thread contention, GC thrashing, and misconfigured caches can turn a minor slowdown into unusable latency.
- Data integrity issues or loss: Corrupted records, duplicated entries, or missing transactions often surface quietly before revealing the true impact. IDC estimates that data integrity problems cost companies an average of $15 million annually.
And sometimes, the consequences are extreme. Knight Capital famously lost 440 million dollars in 45 minutes due to a software configuration error that slipped through testing.
These are the kinds of incidents that permanently reshape how organizations think about quality.
Security & Compliance Crises
Not every crisis crashes your system. Some expose your organization to risk quietly: an unpatched library, a permissive access control, a misconfigured API gateway, or an unintentionally created privacy loophole by a product management decision.
Security and compliance failures are hazardous because the impact extends far beyond engineering.
Verizon’s 2024 DBIR found that 68 percent of breaches involved vulnerabilities that could have been avoided with timely patching.
Breaches also become more expensive the longer they stay undetected.
Organizations that respond quickly to breaches save an average of 1.9 million dollars compared to slower responders.
These crises often take the form of:
- Exploitable vulnerabilities in production. SQL injection windows, authentication bypasses, forgotten endpoints, or unscanned third-party dependencies.
- Data breaches or unauthorised access. This immediately becomes a legal, compliance, and communications issue.
- Compliance failures. Missing PCI-DSS requirements, weak encryption practices, unverified logging, or incomplete audit trails can trigger penalties of 5,000 to 100,000 dollars per month depending on severity.
- Privacy violations. Even if unintentional, exposing user data through risky defaults or misaligned UX decisions quickly destroys trust.
- Audit findings requiring immediate remediation. Failed security audits or missing documentation can halt certifications, delay renewals, and force last-minute remediation work.
A well-known example is the launch of Healthcare.gov in 2013. The platform went live with significant untested components, creating major privacy and security concerns.
The project’s own Chief Security Officer warned that they had “no confidence that Personal Identifiable Information will be protected.”
Security crises are different from production crashes because they linger. Even after a technical fix, the reputational and regulatory fallout can last years.
Organizational Crises
Some crises start long before a defect reaches production. These grow silently inside teams, processes, or culture.
Unlike a production outage, organizational crises do not show up as an alert. They show up as friction, exhaustion, missed deadlines, or growing mistrust.
These crises emerge when quality problems overwhelm people, not just systems.
The World Quality Report found that 54% of QA leaders struggle with coverage and prioritization due to rising complexity and limited resources.
Common organizational crises include:
- Missed launch dates due to late-found defects: The root issue is often not QA performance, but late QA involvement or weak definitions of done.
- Overwhelming defect volume: When teams drown in bugs, they lose the ability to think strategically and shift into reactive testing.
- Loss of key QA personnel at critical moments: Without shared knowledge or documentation, even one departure can stall releases.
- Erosion of stakeholder trust: Repeated failures make leaders question QA effectiveness and push teams to skip steps “just this once.”
- QA authority being overridden by pressure: When quality gates or sign-offs are ignored, a future crisis becomes almost inevitable.
These crises are dangerous because they reshape culture. Once trust erodes or quality shortcuts become habits, the team becomes primed for bigger failures later.
Your First Line of Defense: Preventing QA Crises
A crisis rarely begins at the moment you notice it. By the time a user reports an error or a dashboard turns red, the real problem has already been growing quietly in the background.
Prevention is where the real work of crisis avoidance happens.
Think of these as your first line of defense, foundational QA practices that stop many issues long before they blow up.
1. Shift-Left Testing & Early Detection
Most crises begin with something simple: a missed assumption, an unclear requirement, a rushed change, or a risk that was never discussed.
Shift-left testing pull testing closer to the moment code is created, so issues surface before they carry business impact.
Foundational shift-left habits include:
- TDD and BDD: Test-driven and behavior-driven development reduce ambiguity early. Microsoft studies found teams using TDD experienced 40–90% fewer defects in production.
- Three Amigos collaboration: When product, development, and QA clarify acceptance criteria together, hidden risks surface before a line of code is written.
- Automated tests in CI: Every commit triggers unit and integration checks, catching regressions within minutes instead of at the end of a sprint.
- Defect density tracking: Early spikes in specific modules often reveal complexity hotspots or unclear logic that could later cause failures.
Early detection is not just about better coverage. It is about catching defects when they are cheapest to fix.
In practice, teams that shift left often see a dramatic drop in customer-impacting incidents.
2. Quality Gates – Your Safety Checkpoints
Think of quality gates as the “go/no-go” checkpoints in your development and release process.
At each gate, predefined criteria must be met for the product to move to the next stage. If the criteria aren’t met, the release stops period.
These gates act as tripwires to prevent ill-prepared releases from sneaking into production.
Below is a simple example of quality gates at various stages:
To implement quality gates effectively, keep the criteria clear, measurable, and automated.
Everyone should know exactly what “passing” means, such as all high-priority tests green, acceptable performance benchmarks, or coverage thresholds met.
Integrate these checks directly into your CI/CD pipeline so builds fail automatically when critical issues appear.
Gates must also be mandatory, with exceptions kept rare and formally approved. They should protect delivery, not slow it, so focus on essential criteria and refine them over time to reduce noise.
3. Risk-Based Testing
Even the most mature QA teams have limited time, limited people, and increasingly complex systems to validate.
Risk-based testing ensures that effort is not spread evenly but intelligently. Instead of treating every feature as equal, teams test the areas where failure would hurt the most.
A practical risk-based approach includes:
- Mapping critical user flows where interruptions cause high business impact
- Assessing modules based on how likely they are to fail
- Prioritizing testing in areas with complex integrations or high change frequency
- Increasing exploratory and negative testing around high-risk components
- Reducing effort on stable, low-risk areas to free time for deeper coverage where needed
The 80/20 pattern is common: 20% of the system often contains 80% of the risk.
Organizations that adopt structured risk-based testing report higher ROI on testing effort because they invest where failure is not an option.
One study noted organizations saw a 35% higher ROI on testing by prioritizing based on risk, since they focused efforts on preventing the most costly failures.
Healthcare and fintech products often concentrate more than 40% of their test effort on data integrity and transaction flows, even though those flows represent a smaller portion of the codebase.
This approach frequently catches defects that would otherwise cause compliance or financial crises in production.
4. Monitoring & Alerting Systems
Even with strong QA practices, things will still go wrong in production.
A small configuration slip, a slow memory leak, or a missed validation can quietly grow into something far more serious.
The real difference between a contained incident and a full crisis is how quickly you notice and respond.
A few signals matter more than anything else:
- Mean Time to Detect (MTTD): How fast you realise something is broken. The best teams detect within minutes because their alerts fire before users complain.
- Mean Time to Resolve (MTTR): How long it takes to recover. Every minute saved reduces downtime, frustration, and revenue loss.
- Defect leakage rate: The percentage of issues escaping into production. A rising rate means upstream testing is losing coverage.
- Reliability indicators: Latency, error rate, availability, transaction success, and page load speed. Breaching these thresholds means something is failing under the surface.
- User-reported signals: Sudden spikes in support tickets, app reviews, or social mentions. If users report issues before monitoring catches them, the monitoring system needs attention.
A reliable monitoring setup begins with real-time visibility into every critical path.
Application performance monitoring, centralised logs, and live dashboards should expose everything from CPU spikes to failing checkout flows.
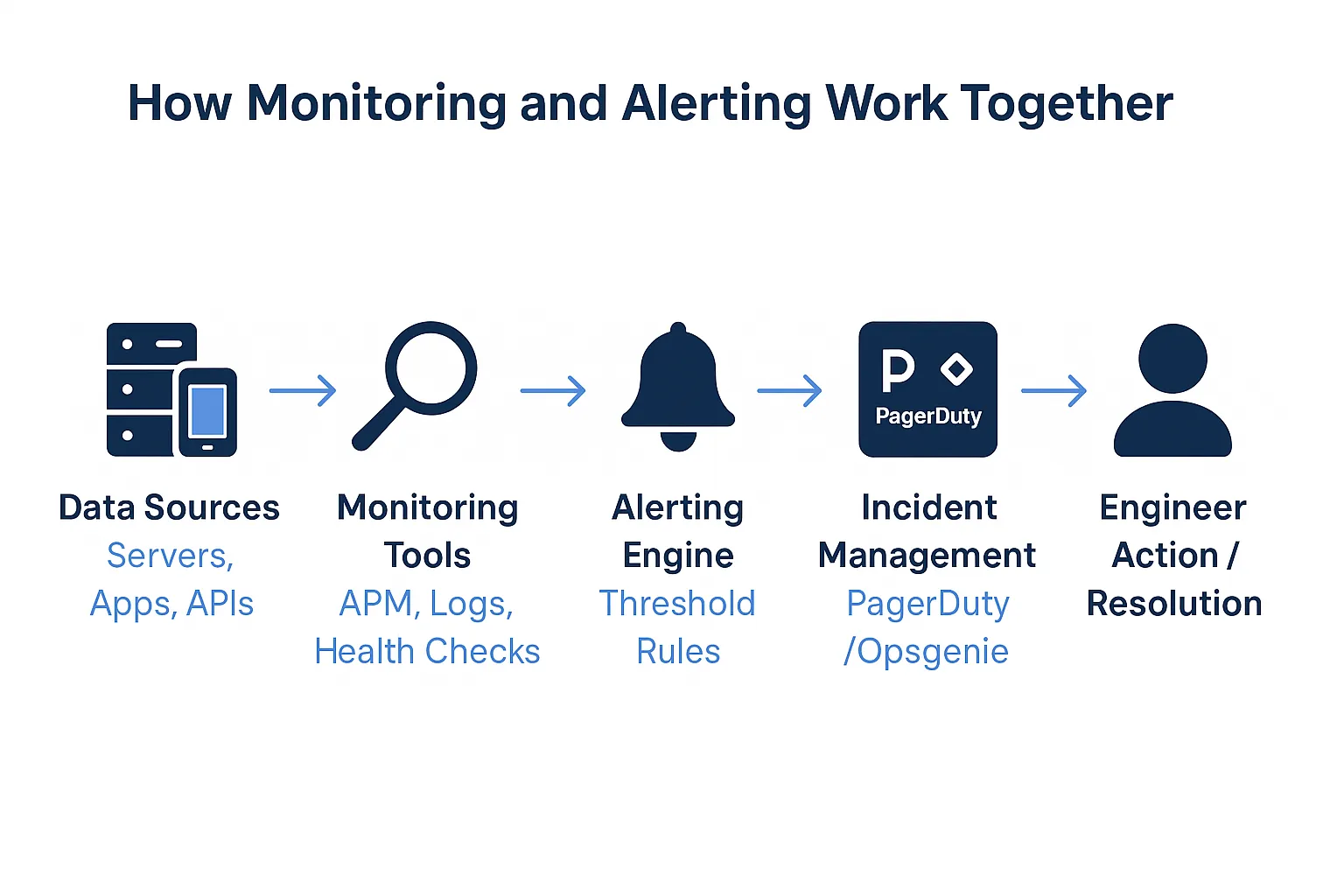
Alerts need to trigger automatically when thresholds are breached, and they should integrate directly into incident workflows so the right person is notified immediately and escalation happens if no one responds.
Thresholds must be tuned carefully. Too sensitive and the noise overwhelms the team; too loose and real incidents slip past unnoticed.
Synthetic checks and health probes add another layer of confidence by catching failures before users hit them.
At the same time, structured logs, correlation IDs, and session replay tools provide the context engineers need to diagnose issues quickly. Context is what turns an alert into a fast resolution.
Teams that invest in proactive monitoring often see up to a 30% drop in customer-impacting incidents within a year.
In the end, monitoring is your crisis insurance. It won’t stop every fire, but it can stop a spark from burning down the house.
Wrapping Up: Building Your First Line of Defense
Quality crises rarely start with the dramatic moment when something breaks in production.
They begin earlier, in the missed assumptions, unclear requirements, weak gates, and untested risks that quietly build pressure over time.
Your strongest defense is the work that happens long before a release goes live. Shift-left habits catch issues when they are easiest to fix.
Quality gates stop unsafe changes from moving forward. Risk-based testing keeps the focus on the areas with the highest business impact. And monitoring picks up the early signals before users feel the pain.
The best QA teams are not defined by having zero bugs. They are characterized by catching problems early, responding quickly, and preventing failures that disrupt customers and slow the organization.
Need backup when prevention isn’t enough?
Testlio’s fully managed, expert-led crowdsourced testing plugs into your release flow to expand coverage across real devices, regions, and edge cases so you catch issues before customers do.
In Part 2, we look at what to do when prevention is not enough and a crisis actually begins, including how to classify, triage, and lead through a high-pressure incident with clarity and control.
Because even with strong defenses, true resilience comes from how you lead under pressure.


