Why Human Judgment Is Non-Negotiable for Agentic AI
Agentic AI is moving from passive prediction to active participation in user journeys. That shift changes how teams approach testing agentic AI.

It now handles support escalations, decides refunds, guides medical triage, recommends financial actions, adjusts device settings, and onboards users within software products.
You can see the brand impact when things go slightly wrong, not catastrophically wrong.
Klarna pushed hard on AI-led customer support, then had to course-correct after service quality concerns.
In 2025, reports described Klarna reassigning engineers and other staff back into customer support roles after leadership acknowledged the AI push had gone too far and negatively affected customer experience.
That is the point. These systems involve judgment, stakes, and consequences. When software begins to act, the standard for oversight changes.
The question stops being, “Is the model accurate?” and becomes, “Was the decision appropriate for this customer, in this context, and at this level of risk?”
The Stakes Are Rising Fast
Agentic features are moving into domains where accuracy alone is not enough.
Healthcare triage, financial guidance, and legal intake screening all involve judgment, escalation, and downstream consequences.
The gap is that deployment is accelerating faster than governance.
In a 2025 EY survey of 975 C-suite leaders across 21 countries, organizations reported strong controls in only three of nine responsible AI areas, including accountability, compliance, and security.
Consumers were also far more worried than executives about accountability for negative AI use and compliance with AI policies.
Financial services show the same pattern. A 2024 NSCP survey found that while 75% of respondents were exploring or using AI internally, only 12% had adopted an AI risk management framework. Just 18% had established a formal testing program.
Legal is moving quickly, too. Legal teams are accelerating adoption as well. A 2025 contracting survey showed AI usage growing 75% year over year.
In these domains, even trained professionals with rigorous certification make mistakes, which is why second opinions, audits, and peer review exist.
If we do not treat agentic AI with at least the same level of scrutiny we apply to human experts, we accept risk without accountability.
The Multi-Agent Reality
In most agentic systems, decisions aren’t made by a single model. Instead, they rely on multiple agents working together, coordinating and handing off tasks to one another.
You have retrieval agents feeding context to reasoning agents, which hand off to action agents, which get checked by verification agents, and so on. This means that agentic AI testing requires teams to validate multi-agent behavior and orchestration, and cover:
- Context Fidelity Across Handoffs: What gets passed between agents and what gets dropped
- Error Propagation: How a degraded output at step two affects the decision at step five
- Conflict Resolution: What happens when two agents receive contradictory signals
- Pipeline-Specific Behavior: Whether the same agent behaves consistently across different orchestration contexts
You cannot catch these failures by replaying individual outputs through an evaluation harness. You need reviewers who can read the full sequence and recognize when something that looks fine in isolation is actually the beginning of a bad outcome.
What Human Reviewers Actually Catch
Agentic AI does not just generate output. It makes decisions inside real user journeys. In that world, "technically correct" is not the same as acceptable, safe, respectful, or trustworthy.
Automated evaluations check whether an output matches a specification. They cannot tell you whether a decision was appropriate for the person receiving it, in that moment, in that context. That gap is where human judgment is irreplaceable.
Behavioral Quality Is Not the Same as Output Accuracy
Output accuracy is table stakes. What teams underestimate is how often a system can hit accuracy benchmarks and still behave badly in production.
For example, a refund decision or an escalation can be policy-compliant and still feel wrong to the customer who received it.
The challenge is that these failures usually do not show up where the decision was made due to second-order effects. Because of multi-agent orchestration, a decision made today could surface as an issue after several agent handoffs. By the time you see the signal, the trace back to the original decision requires work most teams are not set up to do.
Testing for this means building scenarios that follow the full customer journey, not just score the output:
- Multi-step interaction scenarios that trace behavior across a complete journey
- Escalation chain validation, specifically testing handoff quality under pressure
- Recovery pattern testing to see what happens after a degraded or ambiguous output
- Session consistency checks to catch behavioral drift across repeated interactions
- Cross-system integration scenarios that expose coordination failures between agents
And accountability needs to be built in from the start, not bolted on after an incident. Regulatory review, internal risk committees, and board-level reporting can’t be run on logs alone. Documented human oversight is what makes those conversations possible.
Even Experts Require Verification Loops
We already accept that high-stakes work needs review:
- Clinical second opinions
- Financial audits
- Software code review
- Legal peer review
Testing Agentic AI should not be treated as an exemption. If senior engineers require code review, autonomous systems that issue refunds or guide financial decisions should operate with comparable verification loops.
How to Involve Human Reviewers Without Killing Velocity
Human-in-the-loop testing does not mean humans approve every response. Leading teams treat judgment as an oversight layer that shows up at the right moments, then feeds improvement back into the system.
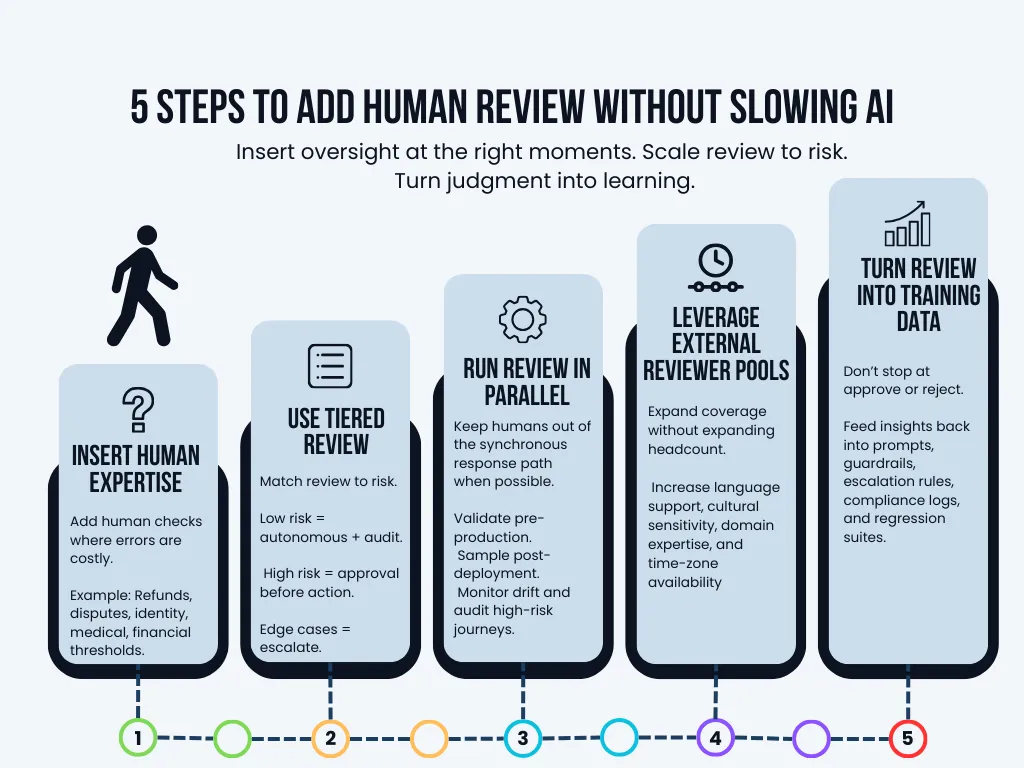
Insert Human Expertise at Critical Quality Gates
Not every decision needs intervention. Focus human review on high-impact boundaries where a wrong action is expensive or irreversible:
- Refund issuance and credits
- Payment reversals and disputes
- Identity verification and account recovery
- Medical urgency classification
- Financial allocation thresholds
Low-risk actions can run autonomously with audit trails. High-risk actions require review before execution. This preserves throughput while containing exposure.
Use Tiered Review Instead of Blanket Review
Blanket reviews slow teams down and create unnecessary friction. Tiered oversight, on the other hand, aligns human involvement with actual business risk.
The principle is simple: Match oversight to impact, not to technical purity.
Not every agentic action carries the same operational, financial, or regulatory consequence. Oversight should scale accordingly.
Run Reviews in Parallel
Avoid putting humans in the synchronous response path unless compliance requires it. Instead, run evaluation alongside delivery:
- Validate scenarios pre-production
- Sample post-deployment interactions
- Monitor drift and escalate outliers
- Run weekly behavioral audits on high-risk journeys
Parallel review keeps velocity high while building accountability and evidence.
Leverage External Reviewer Pools
One thing that breaks down fast when you move into multi-agent, multi-market systems is reviewer coverage.
You ship a feature that handles financial disputes in three languages across two regulated markets. Your internal QA team covers one language and culture well but lacks domain depth in the others, resulting in a systematic blind spot.
A response that reads as appropriate in one market reads as hostile in another. A triage recommendation that is clinically reasonable in one regulatory environment is out of scope in another.
Testing these scenarios effectively requires reviewers who know the market, your users, and the regulatory pressures your product faces across geographies. However, building that breadth internally is slow and expensive, and it pulls engineering and QA leads into hiring and management work that is not core to what they are building.
Managed testing partners with distributed reviewer models exist precisely to close these gaps without adding permanent headcount. They provide scalable, on-demand coverage across languages, regions, cultures, industries, and time zones.
Treat Review Output as Structured Training Data
Human judgment should not end at “approve” or “reject.” Turn it into a reusable signal:
- prompt refinement and guardrail updates
- escalation and handoff rules
- compliance evidence and documentation
- drift detection and regression suites
Oversight becomes a learning loop, not gatekeeping.
Oversight Is the New Infrastructure
Testing agentic AI systems requires a new approach. One that is fundamentally different from how we tested software before.
Regulators and customers alike are demanding transparency and documented evidence that AI models and agents behave responsibly and ethically. Automated evaluations alone won’t help you deliver that. That’s why human reviewers are becoming part of the deployment fabric for testing agentic AI, alongside code review, security auditing, and compliance certification.
The teams that get it right won’t completely remove human reviewers from the equation. Instead, they’ll be the ones who thoughtfully build the infrastructure and processes to integrate human reviewers at scale without slowing down release velocity or creating new bottlenecks.
This is where managed testing partners like Testlio, who provide structured human evaluation, distributed reviewer pools, and scalable oversight models, can help.
With a highly skilled and vetted global community available on demand in 150+ countries, we help teams fully validate agentic AI experiences across languages, markets, and regulated domains at speed and scale.

.png)